引入
当成功区分出内存中存活对象和死亡对象后,GC接下来的任务就是执行垃圾回收,释放掉无用对象所占用的内存空间,以便有足够的可用内存空间为新对象分配内存。目前在JVM中比较常见的三种垃圾收集算法是
- 标记-清除算法(Mark-Sweep)
- 复制算法(Copying)
- 标记-压缩算法(Mark-Compact)
当成功区分出内存中存活对象和死亡对象后,GC接下来的任务就是执行垃圾回收,释放掉无用对象所占用的内存空间,以便有足够的可用内存空间为新对象分配内存。目前在JVM中比较常见的三种垃圾收集算法是
JVM-039-垃圾回收-MAT与JProfiler的GC Roots溯源
为了实时分析GC Roots是哪些东西,中间需要用到一个dump的文件
JVM-038-垃圾回收-对象的finalization机制
finalization)机制来允许开发人员提供对象被销毁之前的自定义处理逻辑。finalize()方法。finalize() 方法允许在子类中被重写,用于在对象被回收时进行资源释放。通常在这个方法中进行一些资源释放和清理的工作,比如关闭文件、套接字和数据库连接等。在堆里存放着几乎所有的Java对象实例,在GC执行垃圾回收之前,首先需要区分出内存中哪些是存活对象,哪些是已经死亡的对象。只有被标记为己经死亡的对象,GC才会在执行垃圾回收时,释放掉其所占用的内存空间,因此这个过程我们可以称为垃圾标记阶段。
那么在JVM中究竟是如何标记一个死亡对象呢?简单来说,当一个对象已经不再被任何的存活对象继续引用时,就可以宣判为已经死亡。
判断对象存活一般有两种方式:引用计数算法和可达性分析算法。
JVM-035-StringTable-intern的使用以及StringTable的垃圾回收
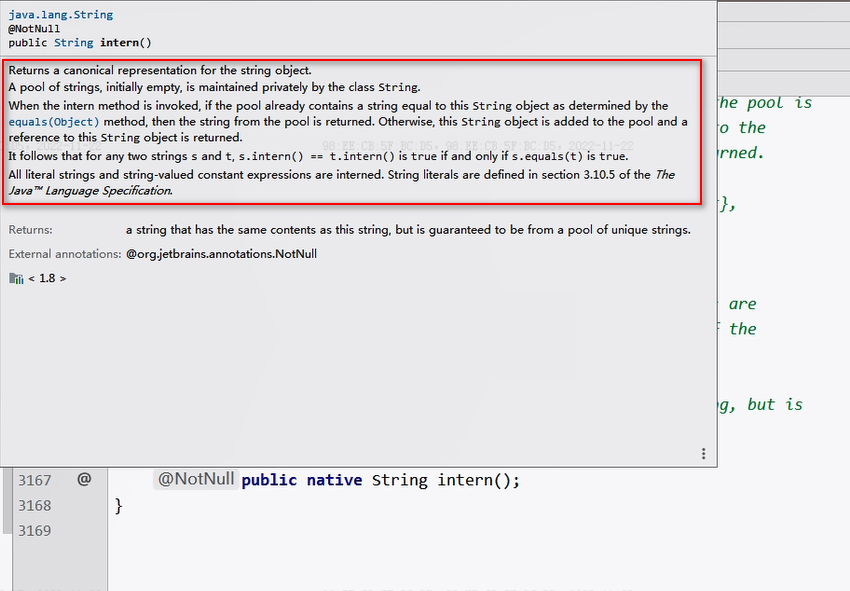
翻译:
字符串常量池最初是空的,由String类私有的维护。在调用intern方法时,如果池中已经包含了由equals(object)方法确定的与该字符串内容相等的字符串,则返回池中的字符串地址。否则,该字符串对象将被添加到池中,并返回该字符串对象的地址。
JVM-033-StringTable-String的概述和基本操作
String在jdk8及以前内部定义了final char value[]用于存储字符串数据。JDK9时改为final byte[] value
官方文档:http://openjdk.java.net/jeps/254
原因:
String类的当前实现将字符存储在char数组中,每个字符使用两个字节(16位)。
从许多不同的应用程序收集的数据表明,字符串是堆使用的主要组成部分,而且大多数字符串对象只包含拉丁字符(Latin-1)。这些字符只需要一个字节的存储空间,因此这些字符串对象的内部char数组中有一半的空间将不会使用,产生了大量浪费。
之前 String 类使用 UTF-16编码 的 char[] 数组存储,现在改为 byte[] 数组 外加一个编码标识存储。该编码表示如果你的字符集编码是ISO-8859-1或者Latin-1,那么只需要一个字节存。如果你是其它字符集编码,比如UTF-8,你仍然用两个字节存
结论:String再也不用char[] 来存储了,改成了byte [] 加上编码标记,节约了一些空间
同时基于String的数据结构,例如StringBuffer和StringBuilder也同样做了修改
1 | // jdk8及之前 |
.java文件转变成.class文件的过程。JIT编译器,Just In Time Compiler)把字节码转变成机器码的过程。AOT编译器,Ahead of Time Compiler)直接把.java文件编译成本地机器代码的过程。(可能是后续发展的趋势)比较常见的编译器:
前端编译器:Sun 的 javac、Eclipse JDT中的增量式编译器(ECJ)。
JIT编译器:HotSpot VM的C1、C2编译器。
AOT 编译器:GNU Compiler for the Java(GCJ)、Excelsior JET。
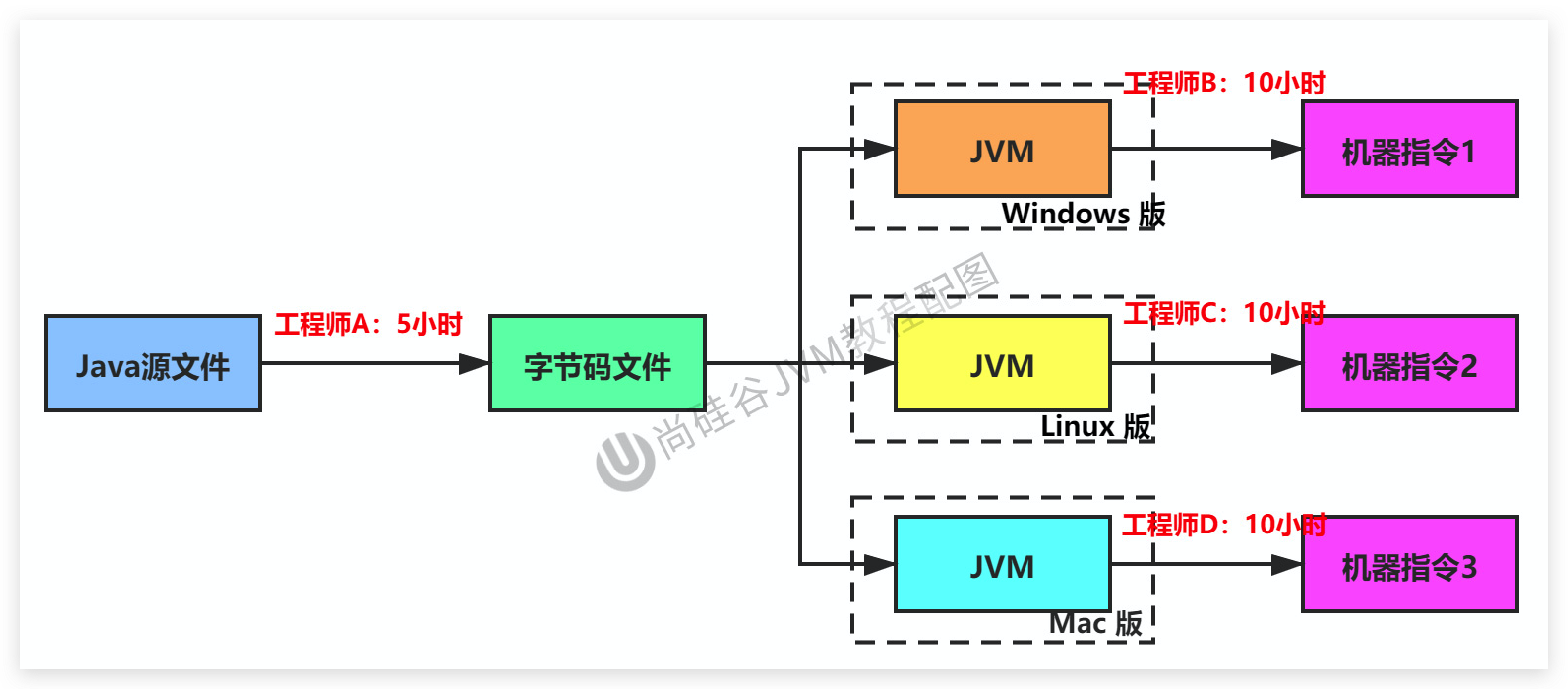
JVM设计者们的初衷仅仅只是单纯地为了满足Java程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法。